
Google researchers have developed a new type of Transformer model that gives language models something similar to long-term memory. The system can handle much longer sequences of information than current models, leading to better performance across various tasks.
The new “Titans” architecture takes inspiration from how human memory works. By combining artificial short and long-term memory through attention blocks and memory MLPs, the system can work with long sequences of information.
One of the system’s clever features is how it decides what to remember. Titans uses “surprise” as its main metric – the more unexpected a piece of information is, the more likely it gets stored in long-term memory. The system also knows when to forget things, helping it use memory space efficiently.
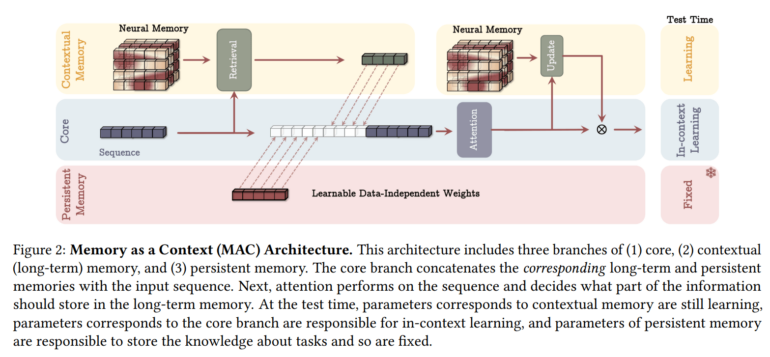
The team created three different versions of Titans, each handling long-term memory differently:
– Memory as Context (MAC)
– Memory as Gate (MAG)
– Memory as Layer (MAL)
Ad
While each version has its strengths, the MAC variant works especially well with very long sequences.
Better performance on long-context tasks
In extensive testing, Titans outperformed traditional models like the classic Transformer and newer hybrid models like Mamba2, particularly when dealing with very long texts. The team says it can handle context windows of more than 2 million tokens more effectively, setting new records for both language modeling and time series prediction with long contexts.
The system also excelled at the “Needle in the Haystack” test, where it needs to find specific information in very long texts. Titans achieved over 95% accuracy even with 16,000-token texts. While some models from OpenAI, Anthropic, and Google perform better, they’re much larger – Titans’ biggest version has only 760 million parameters.
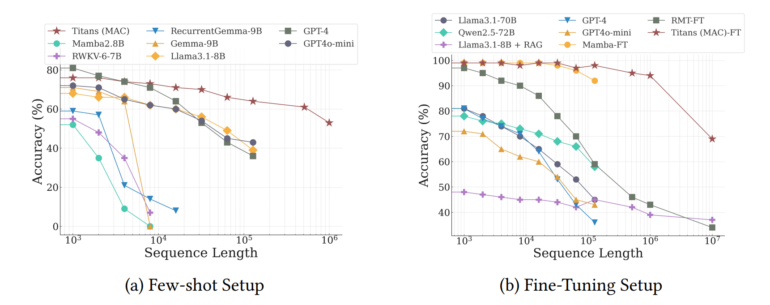
Titans really showed its strength in the BABILong benchmark, a challenging test of long-term comprehension where models need to connect facts spread across very long documents. The system outperformed larger models like GPT-4, RecurrentGemma-9B, and Llama3.1-70B. It even beat Llama3 with Retrieval Augmented Generation (RAG), though some specialized retrieval models still perform better.
The team expects to make the code publicly available in the near future. While Titans and similar architectures could lead to language models that handle longer contexts and make better inferences, the benefits might extend beyond just text processing. The team’s early tests with DNA modeling suggest the technology could improve other applications too, including video models – assuming the promising benchmark results hold up in real-world use.

{kind=link}