
{kind=link}
Sound is a critical part of making a good video. This is why, despite the realism of the output from tools like Google’s Veo, OpenAI’s Sora, and Runway’s Gen-3 Alpha, the videos often feel lifeless. Google Deepmind’s latest AI model hopes to fill this void by generating synchronized soundtracks for your video. It’s pretty wild.
Google’s V2A (video-to-audio) technology combines video pixels with optional text prompts to create audio that closely aligns with the visuals. It can generate music, sound effects, and even dialogue that aligns with on-screen action.
Under the hood, V2A uses a diffusion-based approach for realistic audio generation. The system encodes video input into a compressed representation, then iteratively refines audio from random noise, guided by the visuals and optional text prompts. The generated audio is then decoded into a waveform and combined with the video.
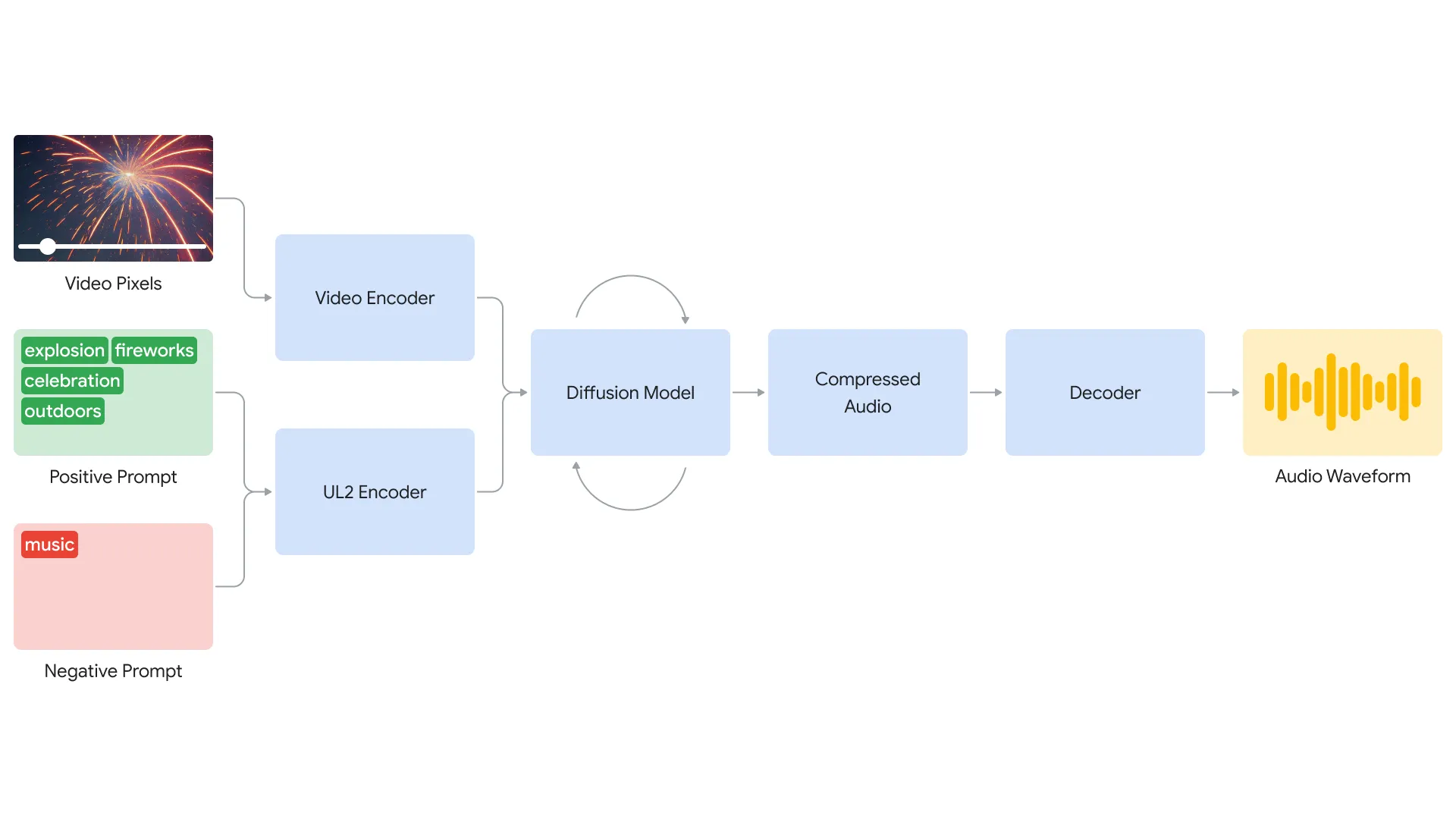
To enhance audio quality and enable more specific sound generation, DeepMind trained the model on additional data like AI-generated sound annotations and dialogue transcripts. This allows V2A to associate audio events with various visual scenes while responding to provided annotations or transcripts.
However, V2A is not without limitations. Audio quality depends on the input video quality, with artifacts or distortions causing noticeable drops. Lip-syncing for speech videos also needs improvement, as the paired video generation model may not match mouth movements to the transcript.
Also, you should know that there are other tools in the generative AI space that are tackling this problem. Earlier this year. Pika labs released a similar feature called Sound Effects. And Eleven Labs’ recently debuted Sound Effects Generator.
Accoding to Google, what sets its V2A apart is its ability to understand raw video pixels. It also eliminates the tedious process of manually aligning generated sounds with visuals. Integrating it with video generation models like Veo creates a cohesive audiovisual experience, making it ideal for entertainment and virtual reality applications.
Google is being very cautious with its release of video AI tools. For now, much to the chagrin of AI content creators, there are no immediate plans for public release. Instead, the company is focusing on addressing limitations and ensuring a positive impact on the creative community. As with their other models, output from their V2A model will include SynthID watermarking to safeguard against misuse.