
{kind=link}
Google is training robots with its Gemini AI so they can complete tasks and navigate spaces more effectively.
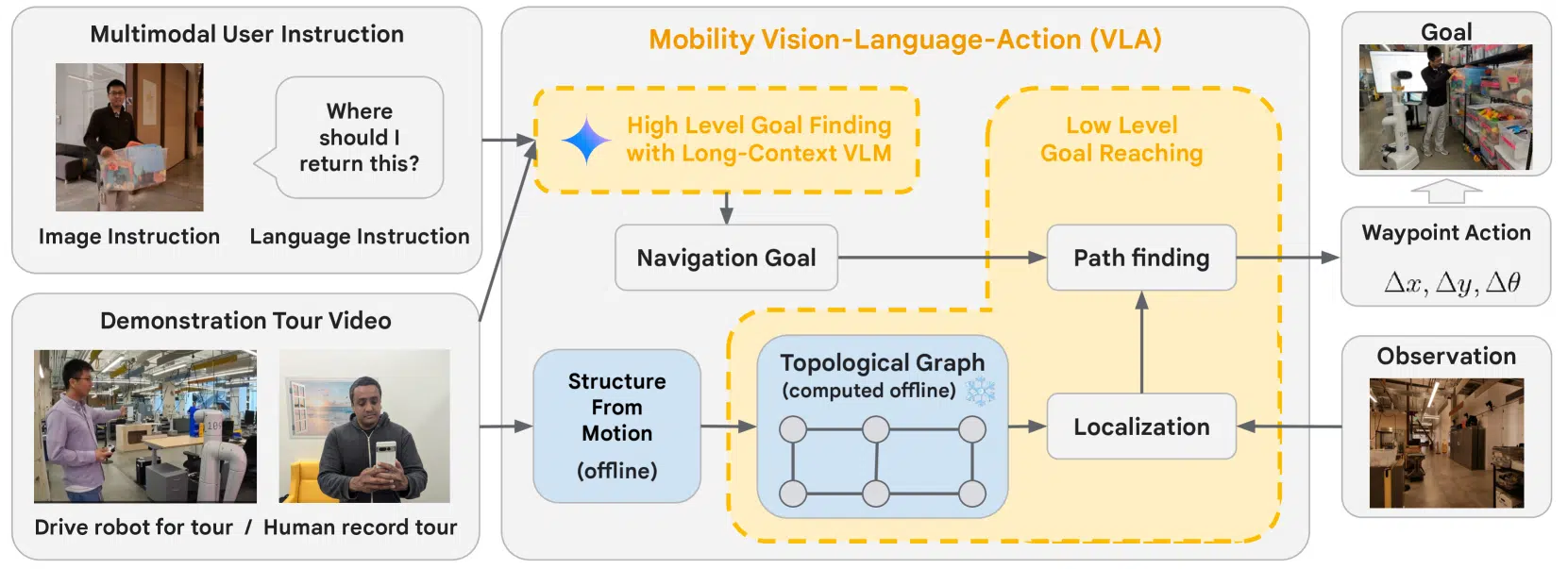
The tech giant’s DeepMind robotics team has paired its Gemini AI engine with RT-2 robots in an attempt to make communication between humans and the bots easier and more natural.
To get the process up and running, the team would film a specific area within the office and then ‘show’ this video to the robot so it could gain an understanding of the environment.
READ MORE! Apple in talks with Google to power iPhone with ‘Gemini AI’ engine
Google is using its Gemini AI to train robots
{kind=link}
A human can then ask a robot a question about that space while using a visual image and the robot will guide the person there.
For example, you could approach the robot and ask, ‘Where can I use this?’ while holding up a whiteboard marker, and it would take you to a whiteboard.
In a recently published paper, Google DeepMind said the AI-powered robots had around a 90 percent success rate when given more than 50 instructions in a 9,000-plus-square-foot area.
This tech would be a big leap forward for AI helpers – allowing humans to interact them with in a way that feels a bit more natural.
The tech could come in useful in real-life situations

“Object goal and Vision Language navigation (ObjNav and VLN) are a giant leap forward in robot usability as they allow the use of open-vocabulary language to define navigation goals, such as ‘Go to the couch’,” the paper’s authors wrote.
“To make robots truly useful and ubiquitous in our daily lives, we propose another leap forward by lifting ObjNav and VLN’s natural language space onto the multimodal space, meaning that the robot can accept natural language and/or image instructions simultaneously.
“For example, a person unfamiliar with the building can ask ‘Where should I return this?’ while holding a plastic bin, and the robot guides the user to the shelf for returning the box based on verbal and visual context.”
Smart stuff, right?
The researchers went on to say that ‘preliminary evidence’ suggested the robots were able to plan how to carry out certain tasks beyond simple navigation.
As an example, the team stacked cans of Coca-Cola on one worker’s desk and then had him ask the robot if his favorite drink was available.
The team said Gemini showed evidence that it ‘knows that the robot should navigate to the fridge, inspect if there are Cokes, and then return to the user to report the result’.
So a bit like a robot butler, then?
Better a robot butler than a robot overlord, right?