
{kind=link}
Google today announced the launch of a 2 billion parameter model to the Gemma 2 family, offering best-in-class performance across diverse hardware, ShieldGemma safety classifiers to filter harmful content, and Gemma Scope tools for researchers to examine decision-making processes.
Check out Gemma 2 2B on Google AI Studio and Hugging Face.
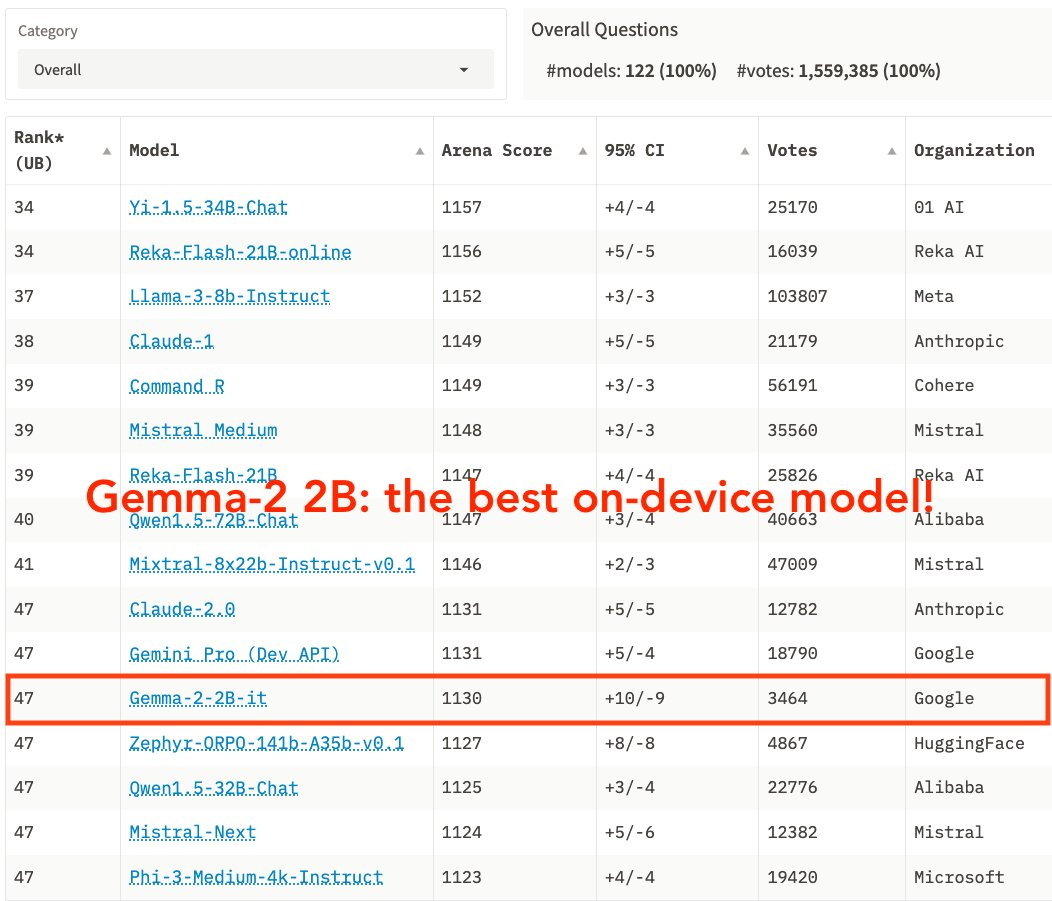
This new model outperformed GPT-3.5 on the Chatbot Arena leaderboard and is optimised for efficient deployment across a wide range of hardware, from edge devices to robust cloud environments. Leveraging NVIDIA TensorRT-LLM library optimisations, it supports deployments in data centers, local workstations, and edge AI applications
Gemma-2-2B, tested as “guava-chatbot,” achieved an impressive score of 1130 in the Arena, rivaling models 10x its size, and outperforming GPT-3.5-Turbo-0613 and Mixtral-8x7b.
“As AI continues to mature, the entire industry will need to invest in developing high-performance safety evaluators. We’re glad to see Google making this investment, and look forward to their continued involvement in our AI Safety Working Group.” said Rebecca Weiss, executive director at ML Commons.
Gemma 3 When?
The release of Gemma 2 2B comes against the backdrop of Meta releasing Llama 3.1, which outperformed OpenAI’s GPT-4o on most benchmarks in categories such as general knowledge, reasoning, reading comprehension, code generation, and multilingual capabilities.
Similarly, last week, OpenAI released GPT-4o mini, a cost efficient LLM. Priced at 15 cents per million input tokens and 60 cents per million output tokens, GPT-4o mini is 30x cheaper than GPT-40 and 60% cheaper than GPT-3.5 Turbo.
The competitive environment in which LLMs operate is changing quickly. Gemma 2’s last update came over a month ago. For Google to stay in the market, it will be essential to innovate and set Gemma apart. It’s high time Google released Gemma 3 to compete with the likes of Llama 3.1 and GPT-4o.