{kind=link}
Google has released the next generation of its open-source vision language model, PaliGemma 2. The new model combines improved image description capabilities with improved performance across multiple applications.
PaliGemma 2 integrates the SigLIP-So400m vision encoder with the complete Gemma 2 language model family (2B to 27B). The system comes in various sizes (3B, 10B, 28B parameters) and supports multiple image resolutions (224px, 448px, 896px), allowing users to scale performance based on their specific needs.
One of PaliGemma 2’s key improvements is its ability to generate more detailed image descriptions. The model doesn’t just identify objects—it can describe actions, emotions, and the broader context of a scene. However, like other generative AI models, it can still produce hallucinations, either describing elements that aren’t present in images or missing visible content.

According to Google, one of the main innovations is the ability to generate detailed and contextually relevant image descriptions. The model goes beyond pure object recognition and can also describe actions, emotions, and narrative contexts in scenes.
Ad
Wide range of applications
According to Google’s technical report, PaliGemma 2 shows strong performance across various specialized tasks. The model can recognize chemical formulas, interpret musical scores, analyze X-ray images, and handle spatial reasoning problems.
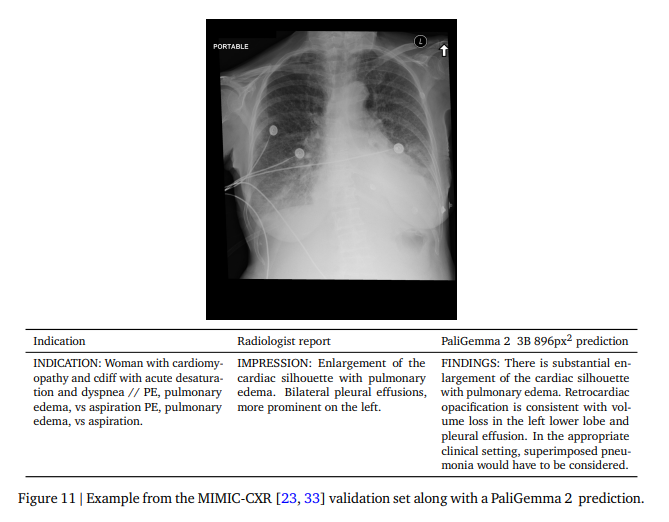
Google says existing PaliGemma users can easily upgrade to version 2, as it’s designed as a direct replacement. The new version offers better performance for most tasks without requiring significant code changes, and users can fine-tune it for specific tasks and datasets.
The model and its code are available through Hugging Face and Kaggle, with Google providing comprehensive documentation and sample notebooks. PaliGemma 2 works with multiple frameworks, including Hugging Face Transformers, Keras, PyTorch, JAX, and Gemma.cpp.
This release adds to Google’s growing Gemma model family, which recently expanded to include new code completion models and more efficient inference capabilities. In late October, Google also introduced a Japanese-optimized Gemma model that achieves GPT-3.5-level performance on Japanese language tasks with just two billion parameters. DataGemma is designed to improve the accuracy and reliability of LLMs by grounding them in real-world data.