{kind=link}
The minute that search engine giant Google wanted to be a cloud, and the several years later that Google realized that companies were not ready to buy full-on platform services that masked the underlying hardware but wanted lower level infrastructure services that gave them more optionality as well as more responsibility, it was inevitable that Google Cloud would have to buy compute engines from Intel, AMD, and Nvidia for its server fleet.
And the profit margins that Intel used to command for CPUs and that AMD now does, and that Nvidia still commands for GPUs and will for the foreseeable future, also meant that it was inevitable that Google would create its own CPUs and AI accelerators to try to lower the TCO on its server fleet, particularly for inside work like search engine indexing, ad serving, video serving, and data analytics in its myriad forms and hyper scales.
And so, every time a Google Cloud event comes around, as one has this week, we get a little more information about the compute engines that Google is buying or building as it assembles its server fleets. Google doesn’t do product launches like normal chip vendors do, with lots of die and package shots and a slew of feeds and speeds and slots and watts. We have to piece it together over time, and wait for a retrospective paper to come out some years hence to find out what Google is actually doing now.
It’s kind of annoying, really. But Google has always been secretive because IT is definitely a competitive advantage for the company, but also bipolar a little in that it wants to brag about its ingenuity because this is what attracts the next round of innovators for the company. All of the hyperscalers and big cloud builders are like this. You would be too if you had such staunch competitors and so much at stake to protect and grow your businesses.
With that said, let’s get into what Google revealed at its keynote about its compute engines, and let’s start with the “Trillium” TPU v6 homegrown AI accelerators.
We did an analysis of the Trillium accelerators back in June, which seems so long ago and which provided as much detail as we could scrounge up on this sixth generation of homegrown AI accelerators from Google. There were many more questions than answers about the TPU v6 devices and the systems that use them, as we pointed out at the time. But we now have some relative performance figures for both inference and training as well as a sense of the relative bang for the buck between the TPU v5e and TPU v6 compute engines.
Amin Vahdat, who used to run networking at Google and who is now general manager of machine learning, systems, and cloud AI, reiterated some of the key aspects of the Trillium TPU in his keynote at Google Cloud App Dev & Infrastructure Summit. The peak performance of the TPUv6 is 4.7X higher than for the TPU v5e that it replaces (somewhat) in the lineup, and has double the HBM memory capacity and bandwidth and double the interchip interconnect (ICI) bandwidth between adjacent TPUs in a system.
Google has also provided some real-world benchmarks for training and inference, which are useful. Here is what the training comparison between TPU v5e and TPU v6 look like:
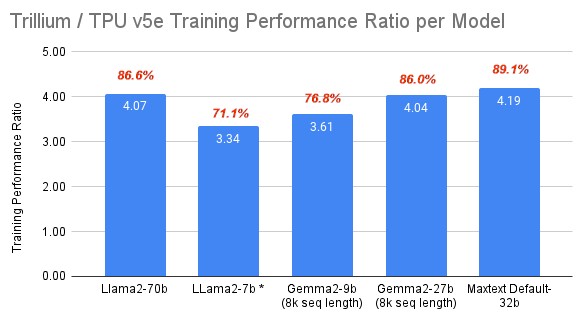
The average performance increase between the current and the penultimate TPU on these five different training benchmarks is 3.85X, which Google is rounding up to 4X in its presentations. We have added the share of peak performance that each benchmark is getting on the benchmark relative to the 4.7X that is inherent in the chippery.
For inference, Google only showed off the performance of Trillium versus TPU v5e on the Stable Diffusion XL text-to-image model from Stability AI, which was just announced at the end of July and is the state of the art:
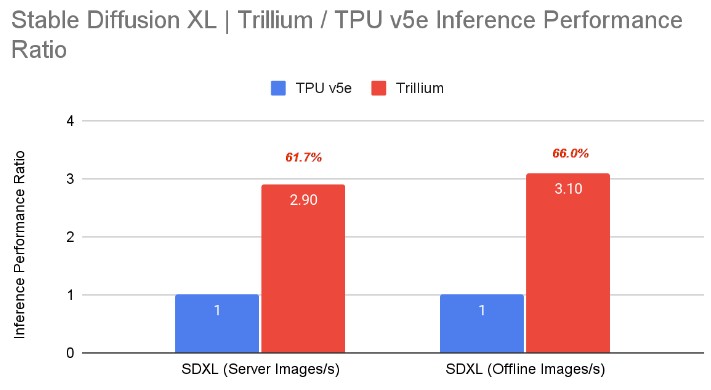
The newness of this code could be why the delta in performance between the TPU v5e and TPU v6 is less than two thirds of the 4.7X delta in peak performance.
It would have been better to see a handful of different inference benchmarks. For instance, where are the benchmark results for Google’s own JetStream inference engine? Moreover, where are the tests comparing the TPU v5p to the Trillium chip?
In its blog describing the benchmarks, Google did say this: “We design TPUs to optimize performance per dollar, and Trillium is no exception, demonstrating nearly a 1.8X increase in performance per dollar compared to v5e and about 2X increase in performance per dollar compared to v5p. This makes Trillium our most price-performant TPU to date.”
We set about trying to use this data to reverse engineer pricing on the TPU v6 from this comparison, and it doesn’t make sense. First, is Google talking about training or inference in these price/performance comparisons, and is it using real benchmarks or peak theoretical performance. Given the divergent pricing for TPU v5p and TPU v5e instances, it is hard to imagine how they can be so close in the multiples in value for dollar that the TPU v6 brings. We poked around and found that even though the Trillium instances are only in tech preview, pricing has been announced. And so we updated our TPU feature and pricing table. Take a look:

As usual, things in bold red italics are estimates made by us in the absence of actual data.
As you can see from this table, the TPU v5p has much larger pods and much higher HBM memory bandwidth than the TPU v5e and half the performance at INT8 and BF16 floating point precision of the TPU v6. As far as we know, the TPU v6 pod size is 256 accelerators in a single image, and that peaks out at 474 petaflops at INT8 precision. Vahdat confirmed this, and then extrapolated beyond the pod.
“Trillium can scale from a single, 256-chip, high bandwidth, low latency, ICI domain, to tens of thousands of chips in a building-scale supercomputer interconnected by a multi-petabyte per second datacenter network,” Vahdat explained. “Trillium offers an unprecedented 91 exaflops in a single cluster, four times that of the largest cluster we built with our previous generation TPU. Customers love our Trillium TPUs, and we are seeing unprecedented demand for the sixth generation.”
Considering that the TPU v6 instances are only in tech preview, it must be a relatively small handful of very important customers who are doing the praising.
Vahdat also showed off some images of the Trillium gear. Here is a TPU v6 system board with four TPU v6 compute engines on it:

And here are some racks of such Trillium iron with a node posing suggestively exposed in front of them.

And now, a pivot to Nvidia GPU infrastructure, which Google Cloud has to build so companies can deploy the Nvidia AI Enterprise software stack if they want to on cloud infrastructure and which also is being tuned up by Google and Nvidia to run Google’s preferred JAX framework (written in Python) and its XLA cross-platform compiler, which speaks both TPU and GPU fluently.
Google has already launched A3 and A3 Mega instances based on Nvidia “Hopper” H100 GPU accelerators with 80 GB and 96 GB of HBM3 memory, and Vahdat took the opportunity to preview new A3 Ultra instances that will be coming soon on Google Cloud that are based on the Hopper H200 GPU, which has fatter 141 GB HBM3E memory. The A3 Ultra instances will be coming out “later this year,” and they will include Google’s own “Titanium” offload engine paired with Nvidia ConnectX-7 SmartNICs, which will have 3.2 Tb/sec of bandwidth interconnecting GPUs in the cluster using Google’s switching tweaks to RoCE Ethernet.
Vahdat did not say much about Nvidia’s announced and ramping “Blackwell” GPUs, but did say that it had “a few functioning Nvidia GB200 NVL72 racks and is actively working on bringing this technology to our customers.”
Vahdat also added that the C4A instances based on Google’s own “Cypress” Axion Arm server CPUs are now generally available. Google announced the first Axion chip back in April, but apparently had two chips in the works, the other code-named “Maple” and based on technology licensed from Marvell and Cypress based on Neoverse V2 cores. The Axion processors are also paired with the Titanium offload engines.
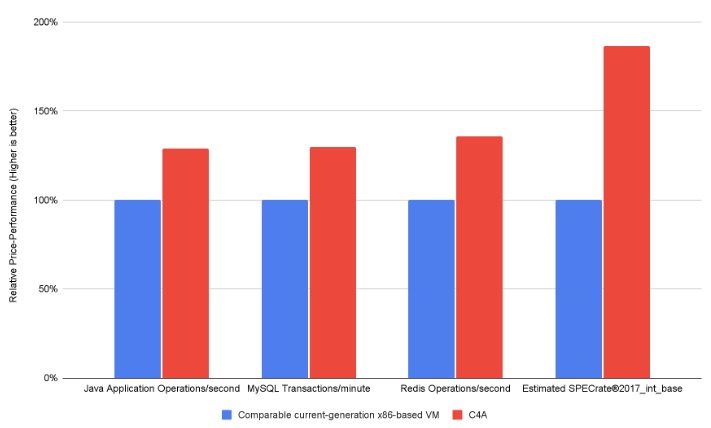
Google said that the C4A instances had 64 percent better price/performance on SPEC integer benchmarks and up to 60 percent better energy efficiency than “current generation X86-based instances,” but did not specify what those instances were. He added that the C4A instances offered 10 percent better performance than other Arm instances out there on other clouds. He did not say what the performance of the Axion processor was compared to an Intel “Granite Rapids” Xeon 6 or AMD “Turin” Epyc 9005 CPU.
And for fun, Google showed this bang for the buck chart:
What we have not known until now is what the Axion C4A instances look like, so here are the speeds and feeds for the standard editions of the C4A instances, which have 4 GB per vCPU:
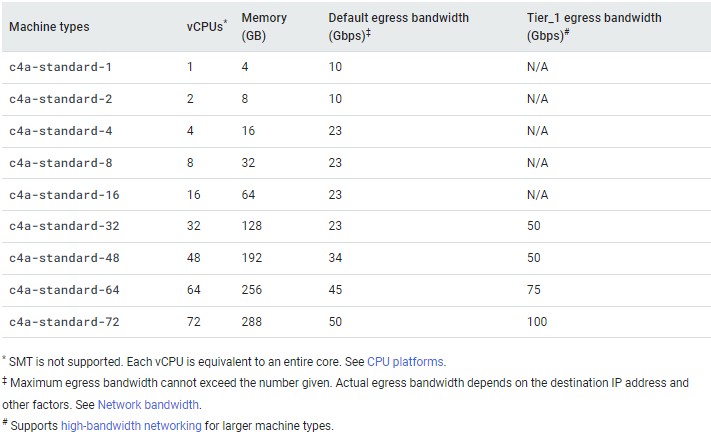
There are high CPU configurations of the Axion C4A instances that have 2 GB per vCPU and high memory configurations that have 8 GB of memory per vCPU. And as the fine print says, these V2 cores in the Axion chip do not support simultaneous multithreading, so a core is a thread is a vCPU.
Here is the hourly pricing for the standard instances in Google’s Northern Virginia (US-East-4) region:
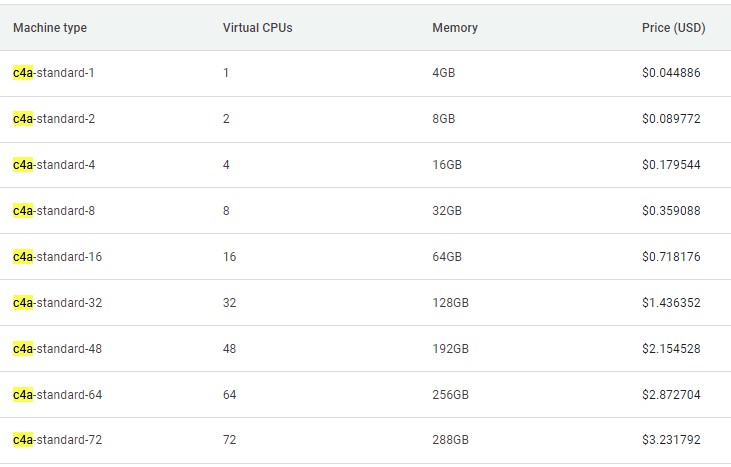
The C4A instances are available in US-Central1 (Iowa), US-East4 (Virginia), US-East1 (South Carolina), EU-West1 (Belgium), EU-West4 (Netherlands), EU-West3 (Frankfurt), and Asia-Southeast1 (Singapore) regions; availability in additional regions is expected “soon.”
We look forward to working up a comparison of AWS Graviton 4, Google Cloud C4A, and Microsoft Azure Cobalt 100 Arm server chips running in those respective clouds. Hopefully Microsoft will roll out the Cobalt 100 at its Ignite 2024 conference in a few weeks so we can do it.
